Why Cerbos runs as a separate process
| This documentation is for a previous version of Cerbos. Choose 0.54.0 from the version picker at the top right or navigate to https://docs.cerbos.dev for the latest version. |
If you’re used to traditional authorization approaches, you’d be surprised to find that Cerbos is not a library that you can embed into your application. Instead, Cerbos is designed to be run as a sidecar or a service alongside your application. There are several reasons why we have chosen this approach. To provide a bit of background, let’s consider how modern software development works in the era of cloud native computing.
Nowadays, the trend is towards microservice architectures where system functionality is split between multiple services that are fairly independent of each other. They are probably owned by different teams within the organization and even developed using different programming languages and tools. Automated CI/CD pipelines deploy new versions of these services many times a day.
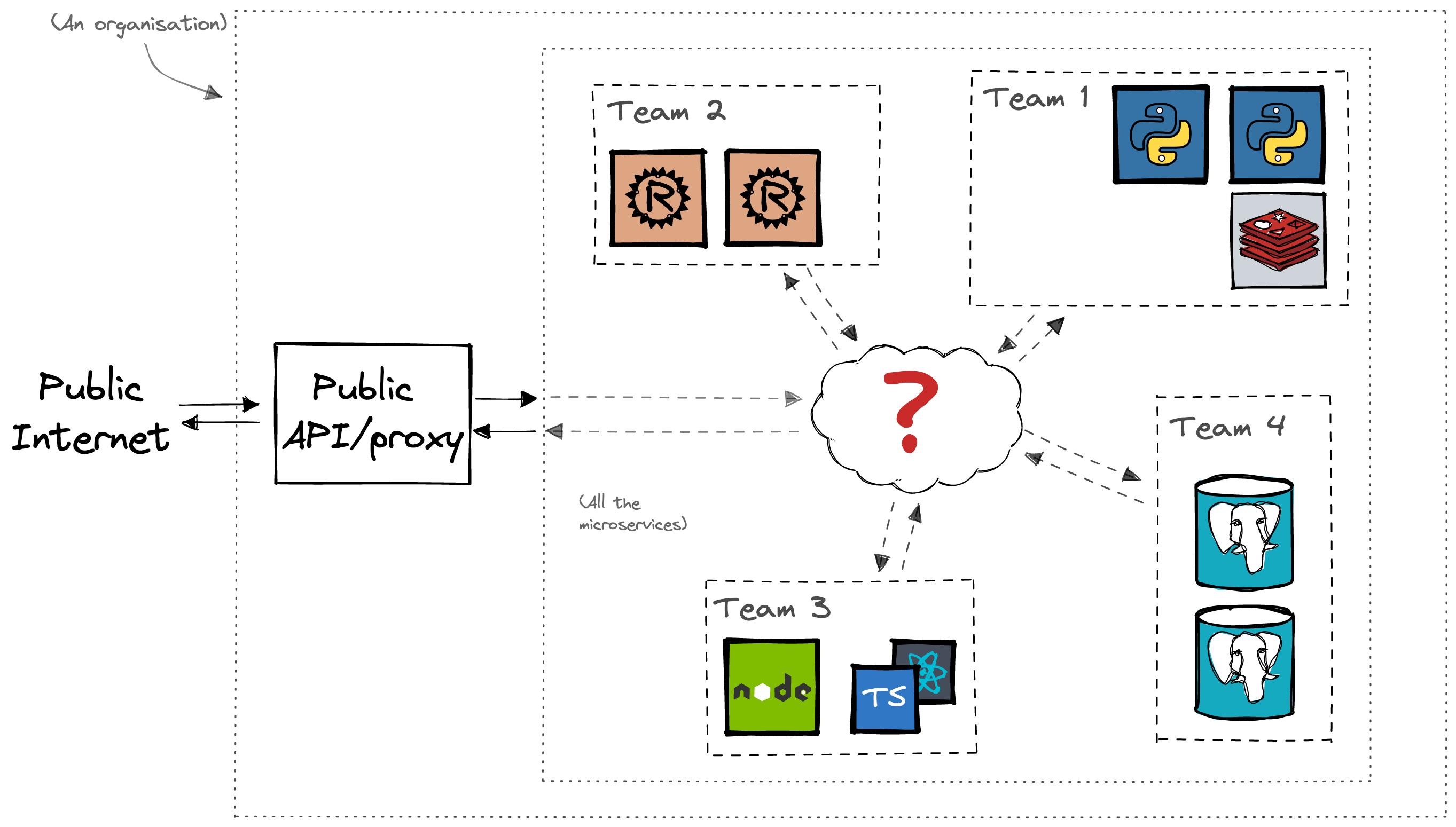
In these dynamic, polyglot environments, the emergent pattern for providing cross-cutting concerns such as service discovery, resiliency, observability and security in a standardized way is through the use of sidecars or other microservices. Frameworks such as Dapr and service meshes such as Istio and Linkerd are examples of software that employ this pattern.
Authorization is one of those cross-cutting concerns that needs to be standardized and centrally managed across the organization. If authorization rules for the same resource are even slightly different between two services, then that creates a security issue. In a polyglot environment, the implementation of access rules would be duplicated between each programming language. This is a waste of effort and an inevitable source of inconsistencies and bugs due to how programmers interpret the specifications or how the particular programming language deals with certain data types or special cases.
Changing access rules for the whole organization requires coordinated effort to develop, test and roll out those changes across the whole fleet. Debugging authorization problems in such an environment is quite difficult because no one has overall visibility of the whole system. The access logic is hidden away in code in multiple repositories. Unless the developers have been extremely disciplined, the quality of debugging aids such as traces, audit trails and tests would vary wildly as well.
Enter Cerbos…
Cerbos is designed to address most of the above problems:
-
Access policies are human-readable and stored in a central repository so that all stakeholders have visibility over the security rules implemented in their organization.
-
Logs, traces, metrics and audit trails are available out of the box and there are supplementary tools such as a policy testing framework, linter and a REPL for debugging issues.
-
Cerbos automatically detects changes to policies and updates itself on the fly. This makes rollout of access policy changes easy and almost instantaneous. For most changes, this means that the dependent services don’t need to have their code updated and rolled out to production. It saves development time and deployment headaches.
-
Offering Cerbos as a decoupled API allows it to be used by any application or service written in any language while providing a consistent experience across the board. Cerbos facilitates sharing access control logic across different services and applications and gets rid of inherent code duplication, inconsistent implementations, version drift and maintenance burden.
By not having to worry about wrapping and shipping Cerbos features into language specific, embeddable libraries, we can focus our time and energy into optimizing the product and building new features using a smaller set of libraries and utilities provided by the language of our choice. We can test these features much more thoroughly because we have full control over all the integration points. We don’t have to be concerned about integrating or being compatible with an almost unlimited set of libraries and frameworks available for every programming language. And we don’t have to expend effort figuring out how to share common code across different languages, fight with language quirks and performance hotspots like foreign function interfaces and concurrency primitives.