Cerbos deployment patterns
| This documentation is for an as-yet unreleased version of Cerbos PDP. Choose 0.53.0 from the version picker at the top right or navigate to https://docs.cerbos.dev for the latest version. |
Cerbos can be deployed as a service or as a sidecar. Which mode to choose depends on your requirements.
| Cerbos PDP is a stateless system that makes decisions solely based on information passed to it by the calling application. This assumes that the communication link between the application and the PDP is secure and tamper-proof. We strongly recommend enabling TLS for the communication link regardless of the deployment model. |
Service model
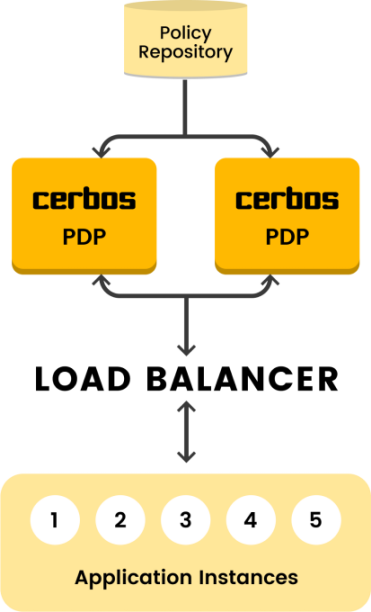
-
Central policy decision point shared by a group of applications.
-
Cerbos can be upgraded independently from the applications — reducing maintenance overhead.
-
In a busy environment, careful capacity planning would be required to ensure that the central Cerbos endpoint does not become a bottleneck.
Sidecar model
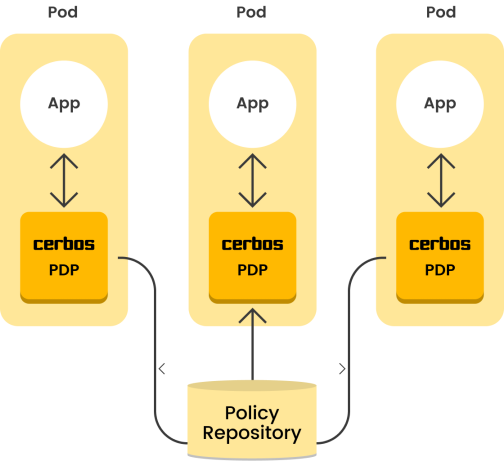
-
Each application instance gets its own Cerbos instance — ensuring high performance and availability.
-
Upgrades to Cerbos would require a rolling update to all the application instances.
-
Policy updates could take slightly longer to propagate to all the individual application instances — resulting in a period where both the old and new policies are in effect at the same time.
DaemonSet model
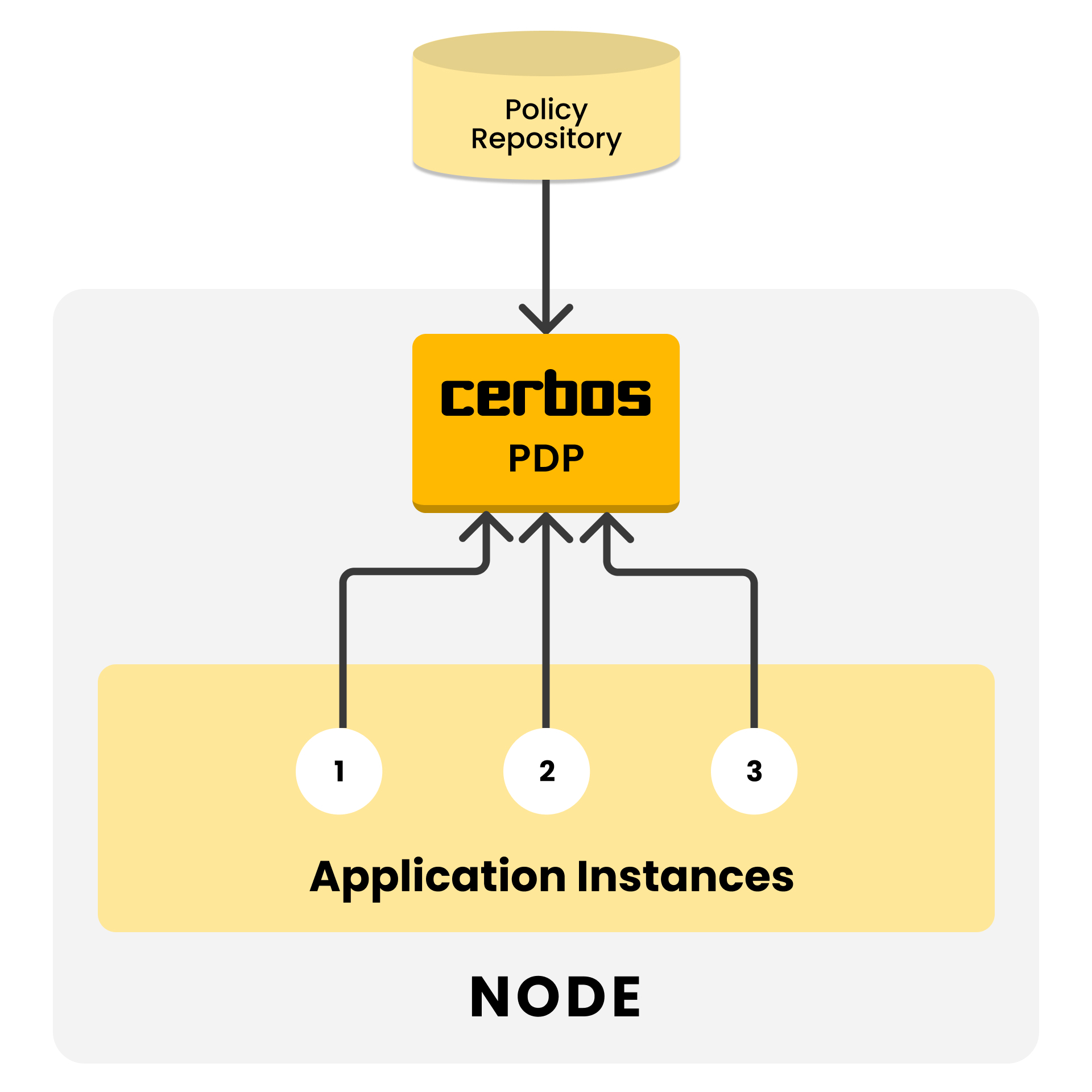
-
Each cluster node gets its own Cerbos instance — ensuring high performance and efficient resource usage.
-
Policy updates must roll out to nodes individually — resulting in a period where both the old and new policies are in effect at the same time.
-
When deployed as a daemonset the service
internalTrafficPolicydefaults toLocal. This causes all requests to the service to be forced to the local node for minimum latency. Upgrades to Cerbos could result in application seeing a short outage to the cerbos instance on their own node, client retries may be neccessary. If this is unacceptable you can setservice.internalTrafficPolicytoCluster. You may be able to improve availability via theservice.kubernetes.io/topology-mode: Autoannotation.
|
For a review of production deployment patterns, scaling characteristics, or operational practices, speak to us. Cerbos Hub provides managed policy distribution, audit log aggregation, and PDP monitoring. |
Choosing a deployment model
| Service | Sidecar | DaemonSet | |
|---|---|---|---|
Latency |
Network hop to central service |
Local (localhost/loopback) |
Local (same node) |
Resource efficiency |
Shared instance, lower total overhead |
One instance per pod, higher total overhead |
One instance per node, moderate overhead |
Scaling |
Scale independently of applications |
Scales with application pods |
Scales with cluster nodes |
Upgrades |
Independent of application deployments |
Requires rolling update of application pods |
Independent of application deployments |
Policy propagation |
Updates propagate to each replica in the service group individually |
Updates propagate to each sidecar individually |
Updates propagate to each node individually |
Availability |
Depends on how many replicas are in the service |
High — each pod has its own instance |
High — each node has its own instance |
Best for |
Non-Kubernetes deployments such as bare metal or Kubernetes deployments where it’s preferable to manage and scale a single service rather than multiple sidecars. |
Latency-sensitive applications, strict isolation requirements |
Less resource consumption than sidecars (one per node compared to one per pod) with similar latency characteristics. |
For most Kubernetes deployments, the sidecar model provides the best balance of performance and reliability. Each application pod gets its own Cerbos instance, eliminating network latency concerns and single points of failure.
The service model is the most flexible method of deployment. It can be as simple as a single instance on a VM or as complicated as a globally-distributed and load-balanced service deployed to multiple data centres.
The DaemonSet model is efficient for large deployments where running a sidecar per pod would be wasteful. It provides node-local performance without the overhead of one Cerbos instance per application pod.
| Cerbos is designed to handle high request volumes with low latency. In benchmarks, the network hop to a central service is typically sub-millisecond within a cluster. Start with the simplest model that meets your requirements. |